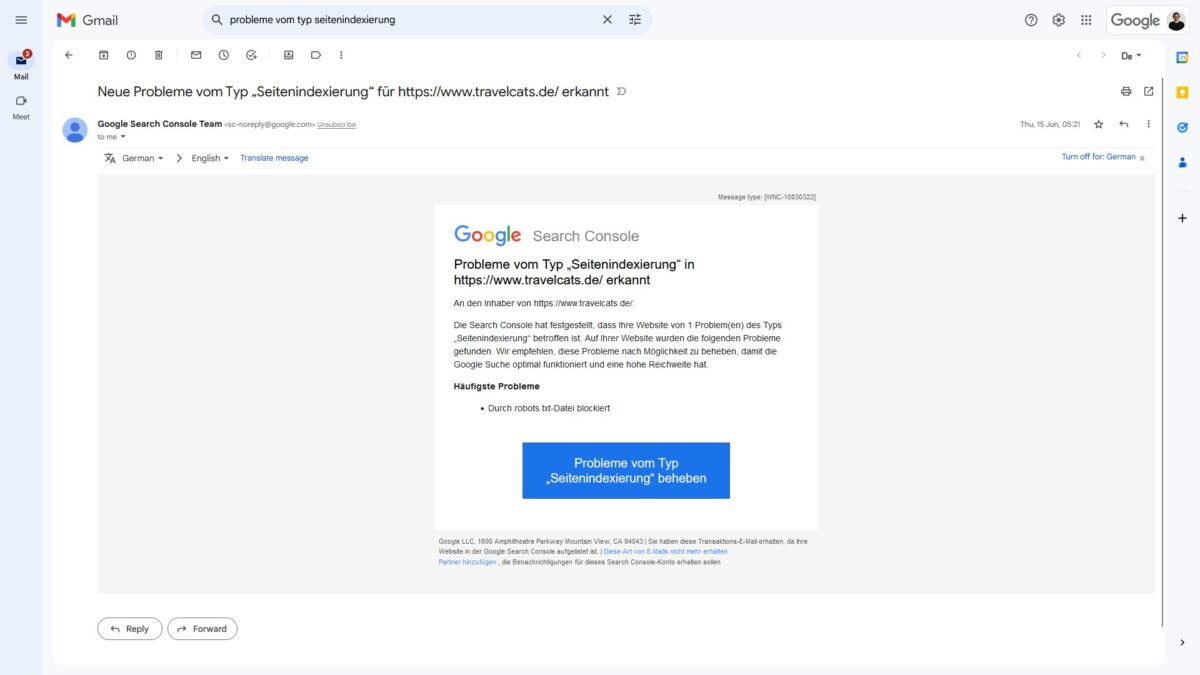
Ohne Indexierung kein Ranking. Deshalb fragen sich viele, wie sie auf die Benachrichtigung der Google Search Console zu „Probleme von Typ Seitenindexierung“ umgehen sollen. Ist die Nachricht ein Problem? Was muss unternommen werden?
Inhalt
- 1 Kurz und knapp: Der Google Indexierungsprozess
- 2 Ein Problem, unterschiedliche E-Mails
- 3 Google meldet Indexierungsprobleme – was nun?
- 4 Die Gründe für Probleme mit der Indexierung in der Google Search Console
- 4.1 Grund 1: Serverfehler (5xx)
- 4.2 Grund 2: Weiterleitungsfehler
- 4.3 Grund 3: URL wird von der robots.txt-Datei blockiert
- 4.4 Grund 4: URL als „noindex“ markiert
- 4.5 Grund 5: Soft 404-Fehler
- 4.6 Grund 6: Wegen nicht autorisierter Anforderung (401) blockiert
- 4.7 Grund 7: Wegen Zugriffsverbot (403) blockiert
- 4.8 Grund 8: URL wegen eines anderen 4xx-Problems blockiert
- 4.9 Grund 9: Durch Tool zum Entfernen von Seiten blockiert
- 4.10 Grund 10: Gecrawlt – zurzeit nicht indexiert
- 4.11 Grund 11: Gefunden – zurzeit nicht indexiert
- 4.12 Grund 12: Alternative Seite mit richtigem kanonischen Tag
- 4.13 Grund 13: Duplikat – vom Nutzer nicht als kanonisch festgelegt
- 4.14 Grund 14: Duplikat – Google hat eine andere Seite als der Nutzer als kanonische Seite bestimmt
- 4.15 Grund 15: Seite mit Weiterleitung
- 5 (K)ein Problem? Die Entscheidung liegt bei dir
Kurz und knapp: Der Google Indexierungsprozess
Damit eine URL von Google indexiert werden kann, muss sie diese Prozessschritte allesamt erfolgreich durchlaufen:
- URL ist Google bekannt,
- die Adresse darf und wurde von Google erfolgreich gecrawlt,
- die Adresse darf indexiert werden und erfüllt Googles Anforderungen.
Erst dann ist eine Seite im sogenannten Google Index und kann in den Suchergebnissen auftauchen. Das Crawling (Schritt 2) kann über die robots.txt-Datei (und die Statuscodes) gesteuert werden, für die Indexierung (Schritt 3) sind sowohl das Canonical-Tag, als auch die robots-Angaben verantwortlich.
Ein Problem, unterschiedliche E-Mails
Wenn Google nun per E-Mail oder in der Google Search Console über „Probleme vom Typ Seitenindexierung“ informiert, dann sind Adressen nicht indexiert worden.
Diese E-Mail zu diesem Problem kann zwei unterschiedliche Betreffzeilen haben:
- Probleme vom Typ „Seitenindexierung“ in [website] erkannt
- Probleme vom Typ „Seitenindexierung“ in den eingereichten URLs für [website] erkannt
Wie im Indexierungsbericht unterscheidet Google bei den Benachrichtigungen zwischen „alle bekannten URLs“ und „alle eingereichten URLs“. Doch was bedeutet das?
- Eingereichte URLs: Alle Webadressen, die über eine XML-Sitemap an Google gesendet werden.
- Bekannte URLs: Alle Webadressen, die Google aus unterschiedlichen Quellen kennt, also neben Sitemaps auch über interne oder externe Links.
Google meldet Indexierungsprobleme – was nun?
Grundsätzlich handelt es sich bei dieser Nachricht nur um einen Hinweis. Google meldet einfach nur, dass mindestens eine Adresse nicht indexiert werden konnte. Die Gründe sind sehr unterschiedlich und können entweder mit der Website selbst, oder mit Google zusammenhängen.
Ob aus der Nachricht eine Aktion erforderlich ist, ist von den betroffenen Seiten abhängig. Wenn wichtige Seiten betroffen sind, dann muss gehandelt werden. Andernfalls kann die Nachricht ohne weitere Aktion zur Kenntnis genommen werden.
Die Gründe für Probleme mit der Indexierung in der Google Search Console
Aktuell gibt es 15 verschiedene „Ursachen“ für eine Nicht-Indexierung von Seiten im Indexierungsbericht der Google Search Console. Bei meiner Website sind aktuell 6 dieser Gründe vorliegend.
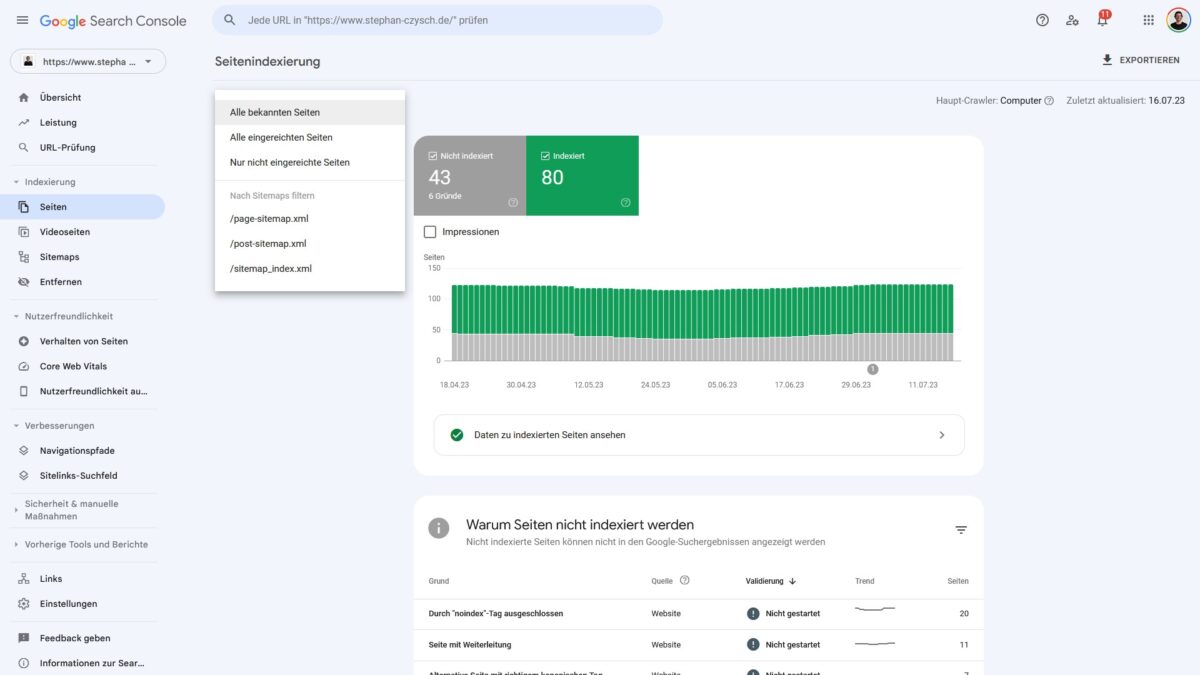
Speziell, wenn du mit dem Bericht arbeitest und nicht direkt auf die Benachrichtigungsemail reagiert hast, solltest du zunächst prüfen, ob das von Google gemeldete Problem überhaupt (noch) vorliegt. Rufe dazu die betroffene(n) Seite(n) in deinem Browser auf. Auch ein Online-Tool wie httpstatus.io kann dir bei der Überprüfung der Seitenerreichbarkeit helfen.
Grund 1: Serverfehler (5xx)
Von einem Serverfehler wird gesprochen, wenn eine Website keine Informationen über die Existenz oder Nichtexistenz einer Adresse liefern kann. Der Server gibt in solchen Fällen normalerweise einen Statuscode im Bereich 5xx zurück, was auf temporäre technische Probleme hinweist.
Wenn du die Adresse in deinem Browser aufrufst und keine Seiteninhalte angezeigt werden, ist es wahrscheinlich, dass nach wie vor ein Serverfehler vorliegt. In diesem Fall empfiehlt es sich, einen technischen Ansprechpartner zu kontaktieren, um weitere Unterstützung zu erhalten.
Grund 2: Weiterleitungsfehler
Von einer Weiterleitung wird gesprochen, wenn eine Adresse auf eine andere Adresse umgeleitet wird. In der Regel antwortet der Server bei Weiterleitungen mit einem Statuscode im Bereich 3xx.
Es gibt zwei häufig verwendete Codes: 301 steht für eine dauerhafte Weiterleitung, während 302 eine temporäre Weiterleitung kennzeichnet. Wenn eine temporäre Weiterleitung verwendet wird, besteht die Möglichkeit, dass die ursprüngliche Adresse wiederhergestellt wird. Die Weiterleitung ist deshalb nur temporär.
Es gibt verschiedene Arten von Weiterleitungsfehlern:
- Weiterleitungsketten: Dies bedeutet, dass mehrere aufeinanderfolgende Weiterleitungen stattfinden. Diese Ketten können zu Problemen führen.
- Weiterleitungsschleifen: Dabei erfolgt eine Verweisung von Seite A auf Seite B und dann wieder zurück auf Seite A. Solche Schleifen enden nie und sollten vermieden werden.
- Weiterleitungen zu Adressen mit zu vielen Zeichen: Es kann vorkommen, dass eine Adresse aufgrund einer fehlerhaften Weiterleitung wiederholt an sich selbst angehängt wird, wodurch die Adresse zu lang wird.
- Weiterleitungen zu nicht (mehr) vorhandenen oder leeren Seiten: Wenn eine Adresse auf eine nicht mehr existierende oder leere Seite weitergeleitet wird, tritt ein Fehler auf.
Um die Adressen zu überprüfen, die von diesem Fehler betroffen sind, empfiehlt es sich, Tools wie httpstatus.io oder ähnliche Dienste zu verwenden. Diese können dabei helfen, den genauen Statuscode der Weiterleitungen zu ermitteln.
Grund 3: URL wird von der robots.txt-Datei blockiert
Mit der robots.txt-Datei können Suchmaschinen der Zugriff mittels Disallow:-Angabe auf bestimmte Adressen untersagt werden. Dadurch weiß die Suchmaschine nicht, ob diese Seite existiert und falls ja, welcher Inhalt sich auf der Seite befindet.
Wenn du feststellst, dass der Zugriff auf eine Seite blockiert ist, solltest du überprüfen, ob dies beabsichtigt ist. Falls nicht, kannst du die entsprechende „Disallow:“-Anweisung in der robots.txt entfernen, um das Crawling der Seite zu erlauben. Dadurch ermöglicht man den Suchmaschinen den Zugriff auf den Inhalt der Seite.
Es ist durchaus legitim, Crawler aus einzelnen Adressen oder Verzeichnissen auszusperren. Mehr dazu erkläre ich auch in meinen Seminaren.
Überprüfen kannst du einen Crawling-Ausschluss mit dem robots.txt-Tester der Google Search Console, oder Browserplugins wie „Robots Exclusion Checker“.
Grund 4: URL als „noindex“ markiert
Indem man den Meta-Robots-Tag „Noindex“ oder den entsprechenden X-Robots-Header verwendet (weitere Informationen findest du in der Google Hilfe), können bestimmte Seiten von der Indexierung durch Suchmaschinen ausgeschlossen werden.
Um zu überprüfen, ob eine bestimmte Seite auf „Noindex“ gesetzt ist, kannst du den Quelltext der Seite durchsuchen und nach dem Begriff „Noindex“ suchen. Alternativ können Browsererweiterungen wie „Robots Exclusion Checker“ hilfreich sein.
Wenn du die betroffenen Adressen bewusst auf Noindex gesetzt hast, ist alles in Ordnung und du musst nichts weiter unternehmen.
Grund 5: Soft 404-Fehler
Ein Soft-404-Fehler tritt auf, wenn eine Seite erfolgreich auf eine Anfrage antwortet und den Statuscode 200 zurückgibt, aber keinen tatsächlichen Inhalt anzeigt.
Wenn diese Seite nicht existieren sollte, empfiehlt es sich, sie zu löschen. Dadurch wird die Serverantwort für diese Adresse auf den Statuscode 404 geändert, was bedeutet, dass die Seite nicht gefunden wurde. Wenn die Adresse Inhalt zeigen sollte, musst du prüfen, warum dies aktuell nicht der Fall ist.
Grund 6: Wegen nicht autorisierter Anforderung (401) blockiert
Wenn der Inhalt einer Seite erst nach erfolgreicher Anmeldung mittels Passwort und Nutzername angezeigt werden kann, erhalten Nutzer, die nicht erfolgreich autorisiert wurden, einen 401-Fehler. Dies bedeutet, dass Google den Inhalt der Seite nicht abrufen konnte.
Überprüfe zunächst, ob der Zugriff auf diese Seite bewusst durch einen Passwortschutz geschützt ist. Wenn dies nicht beabsichtigt ist, empfiehlt es sich, den Zugriffsschutz zu entfernen, damit der Inhalt für alle Nutzer zugänglich ist.
Grund 7: Wegen Zugriffsverbot (403) blockiert
Ein weiterer Fehlercode ist der Statuscode 403, den der Server zurückgibt, wenn eine Anfrage nicht erfolgreich ist, weil die Zugangsdaten nicht korrekt sind.
Da Google sich niemals auf Seiten anmeldet, handelt es sich hier um einen „falschen“ Fehlercode. Die korrekte Vorgehensweise wäre, nicht übermittelte Anmeldedaten mit dem Statuscode 401 zu beantworten, um anzuzeigen, dass eine Authentifizierung erforderlich ist.
Grund 8: URL wegen eines anderen 4xx-Problems blockiert
In diese Fehlergruppe werden alle weiteren Fehler eingeordnet, bei denen der Server mit einem Statuscode im Bereich 4xx geantwortet hat.
Um den genauen Statuscode zu ermitteln, kannst du wiederum ein Tool wie httpstatus.io verwenden. Das Online-Tool hilft dabei, den spezifischen Statuscode für die entsprechende Anfrage zu identifizieren.
Grund 9: Durch Tool zum Entfernen von Seiten blockiert
Durch das Tool zum Entfernen von Seiten können Inhalte aus verschiedenen Gründen von Dritten blockiert worden sein, beispielsweise aufgrund persönlicher Daten oder auf Antrag des Website-Verantwortlichen. Das Tool ist sowohl in der Google Search Console für Websiteverantwortliche verfügbar, als auch unter der dieser Adresse für Dritte.
Wenn Adressen aus diesem Grund blockiert wurden, solltest du überprüfen, wer die Entfernung beantragt hat und ob diese Adressen tatsächlich aus dem Index genommen werden sollen.
Grund 10: Gecrawlt – zurzeit nicht indexiert
Wenn Google eine Adresse aufgerufen („gecrawlt“), aber dann trotz Erlaubnis nicht indexiert hat, ist es durchaus ein Problem, was näher analysiert werden muss. Offensichtlich hat Google die Content-Qualität der Seite nicht gefallen.
Dieses Problem zu beheben ist mit das Wichtigste rund um den Indexierungsbericht.
Grund 11: Gefunden – zurzeit nicht indexiert
Wenn Google eine Adresse als „gefunden“ angibt, bedeutet das, dass die Adresse bekannt ist. Es wurde jedoch noch kein Besuch auf dieser Adresse registriert. Es besteht die Möglichkeit, dass Google die Seite zu einem späteren Zeitpunkt besucht, aber es ist nicht garantiert.
Da diese Adressen auf der ersten Stufe des Indexierungsprozesses stehen bleiben (Auffindbarkeit gegeben, aber noch nicht besucht), ist es wichtig, genauer zu untersuchen, was das Problem verursacht.
Auch dieses Indexierungsproblem bedarf einer genaueren Analyse.
Grund 12: Alternative Seite mit richtigem kanonischen Tag
Der Einsatz des Canonical-Tags ermöglicht es Suchmaschinen, die richtige Seite zu identifizieren und den Inhalt korrekt zu indexieren, wenn es ähnliche oder doppelte Seiteninhalte unter verschiedenen Adressen gibt.
Ein gutes Beispiel dafür ist die Druckversion eines Artikels, die unter einer eigenen Adresse verfügbar ist. Diese stellt eine Kopie des eigentlichen Artikels dar. Idealerweise verweist die Druckversion mittels des Canonical-Tags auf die richtige Artikelseite. Dadurch wird Google ein starkes Signal gesetzt, wie mit diesem Duplicate Content umgegangen werden soll.
Dieser Grund für eine Nicht-Indexierung sollte lediglich als Hinweis betrachtet werden, solange die Adressen nicht fälschlicherweise zusammengefasst wurden.
Grund 13: Duplikat – vom Nutzer nicht als kanonisch festgelegt
Bei Adressen, die dieser Gruppe zugeordnet werden, ist Google der Ansicht, dass diese einen ähnlichen Inhalt haben, aber kein Canonical-Tag als zusätzliche Anweisung gesetzt wurde.
Solange Google die „richtige“ Seite als kanonisch identifiziert hat, ist alles in Ordnung. Deshalb einmal schauen, welche Adresse Google als kanonisch wertet. Treten Probleme bei der Auswahl der kanonischen Adresse auf, dann am besten selbst die Canonical-URL wählen.
Grund 14: Duplikat – Google hat eine andere Seite als der Nutzer als kanonische Seite bestimmt
Es kann vorkommen, dass Seiten mittels des Canonical-Tags miteinander verknüpft wurden, Google jedoch diese Seiten nicht als ähnlich oder kanonisch betrachtet. Da das Canonical-Tag lediglich als Empfehlung angesehen wird, gibt diese Fehlergruppe Auskunft darüber, bei welchen Adressen Google eine andere Seite als kanonisch betrachtet als der Nutzer.
Auch bei dieser Fehlergruppe ist es wichtig, zu überprüfen, ob möglicherweise Fehler in den Canonical-Tags vorliegen. Dafür müssen die betroffenen Seiten einzeln analysiert werden, um festzustellen, warum Google die Kanonisierung anders interpretiert als beabsichtigt. Eine sorgfältige Überprüfung und Anpassung der Canonical-Tags kann dazu beitragen, dass Google die gewünschten Seiten korrekt als kanonisch erkennt.
Grund 15: Seite mit Weiterleitung
Wenn eine Adresse auf eine andere Seite weiterleitet, dann kann sie logischerweise nicht indexiert werden. Hier muss geschaut werden, ob alle Weiterleitungen wie gewünscht von Google interpretiert werden, und keine unbeabsichtigten Weiterleitungen stattfinden.
Wenn sich beispielsweise die Adress-Struktur der Website ändert und Weiterleitungen eingerichtet sind, dann sollte die Anzahl der Seiten in dieser Gruppierung ansteigen.
(K)ein Problem? Die Entscheidung liegt bei dir
Für deinen SEO-Erfolg ist es wichtig, dass deine wichtigen Seiten korrekt indexiert wurden. Deshalb sollten diese Adressen in keiner der Fehlergruppen auftauchen. Andernfalls gibt es ein temporäres Problem, welches du beheben musst.
Google selbst weiß nicht, welche Adressen für die Website besonders wichtig sind. Mit der Nachricht zu „Probleme vom Typ Seitenindexierung“ sagt Google einfach nur „hier sind ein paar Adressen, die ich gefunden, aber nicht indexieren konnte“. Manchmal ist das gewünscht, manchmal nicht.
Um noch mehr über die Google Search Console zu erfahren, wirf einen Blick auf meine Seminare. In diesen gehe ich nochmals tiefer auf den gesamten Bereich der Indexierung ein.
Wenn du einfach nur die Indexierung beziehungsweise ein erneutes Crawling initiieren möchtest, dann schau bei getindexed.io vorbei. Das ist meine Lösung für die schnellere (neu-)Indexierung von Inhalten.



Schreibe einen Kommentar