Mit dem Namen Googlebot wird der Webcrawler von Google bezeichnet. Webcrawler sind computergesteuerte Programme, die den Inhalt („Content“) von Webdokumenten analysieren und diese Inhalte gegebenenfalls in ihren Index aufnehmen. Im Falle von Google ist dies der Google-Index. Nur im Index enthaltene Seiten (oder auch Dokumente genannt) können in Suchergebnissen angezeigt werden.
Beim Zugriff des Googlebots auf einen Webserver macht sich dieser über den sogenannten User-Agent kenntlich. Dadurch ist es bei einer Analyse der Serverlogfiles möglich, die einzelnen Seitenaufrufe des Crawlers nachzuvollziehen. Doch auch in der Google Search Console ist ein Einblick in das Crawlingverhalten möglich.
Die User-Agents des Googlebot
Neben dem „allgemeinen“ Googlebot gibt es Crawler, die für spezielle Themen geschaffen wurden. So gibt es z.B. einen Googlebot für Nachrichten, der sich mit eigener Nutzerkennung auszeichnet. Nachfolgend sind einzelne Google-Crawler und deren User-Agent aufgelistet:
- Google Websuche: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
- Googlebot für Nachrichten: Googlebot-News
- Googlebot für Bilder: Googlebot-Image/1.0
- Googlebot für Videos: Googlebot-Video/1.0
- Googlebot für Adsense: Mediapartners-Google
In der Regel crawlt Google Websites über einen mobilen User-Agent, um die mobile Darstellung einer Seite sehen zu können. In der Google Search Console unter Einstellungen zeigt Google an, welcher Crawler für eine Website bevorzugt zum Einsatz kommt.
Die Übersicht über die verschiedenen User-Agents der Google-Crawler finden Sie hier. Zudem hat Google die verwendeten IP-Adressen zur Verfügung gestellt.
Wie crawlt Google das Netz?
Crawling und die darauf folgende Indexierung sind durchaus komplexe Prozesse. Denn das Web ist sehr groß und dynamisch. Jeden Tag kommen viele neue Inhalte hinzu, die Suchmaschinen wie Google erstmal finden und erfassen müssen. Zudem wächst die Anzahl bereits bekannter (und indexierter) Seiten – auch diese müssen regelmäßig erneut erfasst werden, da sich die Inhalte verändern können.
Neben inhaltlichen Aktualisierungen können sich auch die Indexierungsangaben verändern – oder die Seiten komplett offline genommen werden. Damit Google keine Änderung verpasst, ist deshalb ein erneutes Crawling unabdingbar.
Herauszufinden, wann sich eine Seite verändert, ist dabei eine Kunst für sich. Während viele Dokumente nie verändert werden (z.B. das Impressum einer Seite), sind andere Seiten wie z.B. Online-Shops oder News-Seiten hochdynamisch. Entsprechend werden Websites unterschiedlich stark gecrawlt.
Im Rahmen der SEOkomm 2021 haben Jan-Peter Ruhso von crawloptimizer und Darius Erdt meiner ehemaligen Agentur Dept den Crawling- und Indexierungs-Prozess sehr genau beschrieben. Unter https://www.crawloptimizer.com/google-indexierungsprozess/ ist die nachfolgend zu sehende Darstellung in größerer Auflösung zu finden.
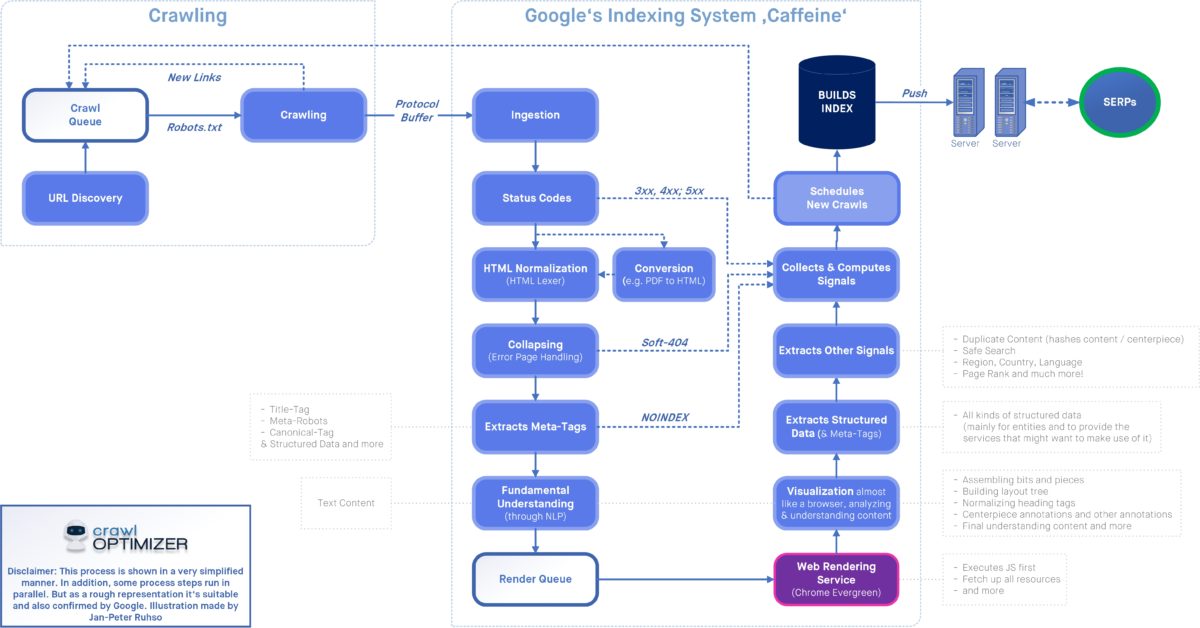
Wer einfach nur die Grundlagen wissen möchte: Das Crawling läuft in der Regel so ab, dass mehrere Instanzen des Googlebot gleichzeitig unterschiedliche Adressen einer Website besuchen. Dabei prüfen die Crawler regelmäßig die robots.txt-Datei, da über diese Datei der Zugriff auf URL-Strukturen blockiert werden kann. Die während des Crawlings erfassten Daten stehen zum Teil in der Google Search Console zur Verfügung.
Nach dem Crawling ist vor der Indexierung: Durch die Verwendung von Meta Robots oder X-Robots mit der Angabe Noindex haben Webmaster die Möglichkeit, die Indexierung einzelner Seiten durch Suchmaschinen zu unterbinden.
Alternativ kann über das Canonical-Tag ein Signal an Suchmaschinen gesendet werden, ob ein Inhalt unter mehrere Adressen vorliegt. Das sogenannte Indexierungsmanagement ist ein wichtiger Baustein einer strategischen Onpage-Optimierung. Über SEO Browserplugins können die Indexierungs- und Crawlingeinstellungen für einzelne Adressen überprüft werden.
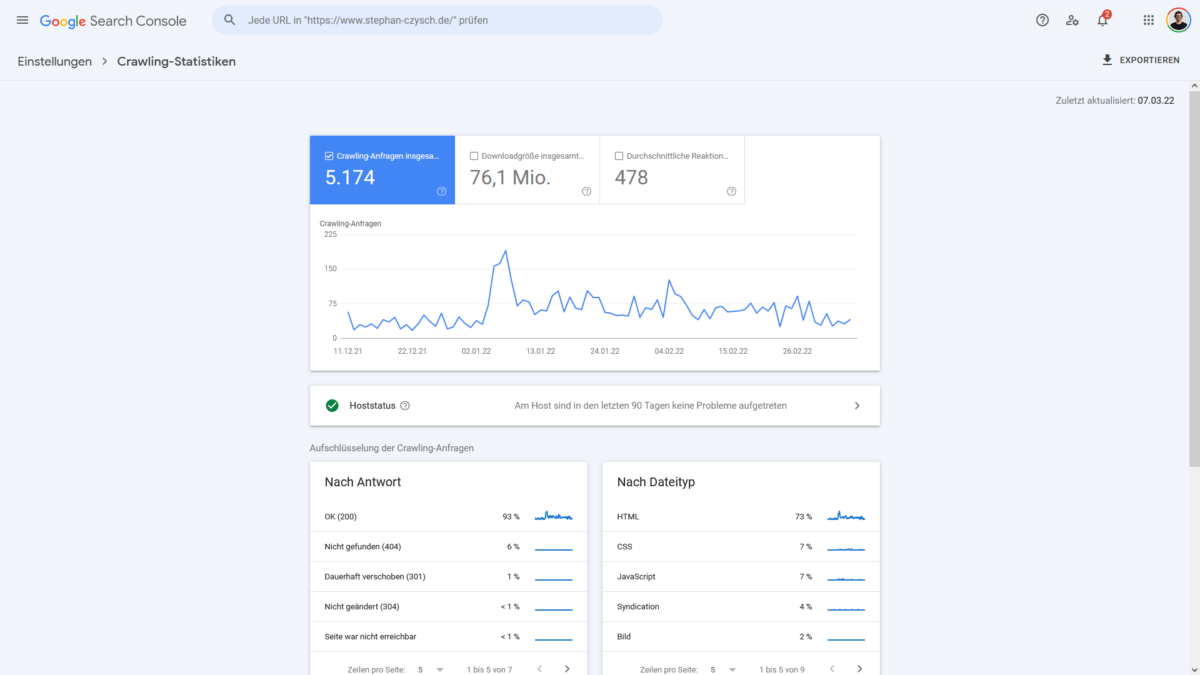
Innerhalb der Google Search Console können Sie unter dem Punkt „Einstellungen“ die sogenannten Crawling-Statistiken aufrufen. Die Statistiken zeigen Ihnen unter anderem, wie viele Seiten Googlebot auf dem Webauftritt analysiert hat.
Weitere Informationen zum Googlebot gibt es in der Google-Hilfe.



Schreibe einen Kommentar