In meinen Schulungen zum Screaming Frog (hier die nächsten Termine) geht ein großer thematischer Block um „Custom Extractions“ und die Frage, wie „nicht-Standarddaten“ aus Webseiten ausgelesen werden können.
Was meine ich damit? Hier geht es z.B. um Kategorietexte, die Integration von Videos und ähnlichem. Ein paar meiner am häufigsten genutzten Custom Extractions teile ich hier öffentlich.
*update vom 28. Juli 2023*
Inhalt
- 1 Custom Extractions dank Screaming Frog 19 visuell definieren
- 2 Dank Custom-Extractions ist mit dem Screaming Frog alles auslesbar
- 3 Den DOM mit XPath, regulären Ausdrücken und CSSPath durchsuchen
- 4 Beispiel-XPaths für den Screaming Frog
- 5 XPaths mit dem Browser generieren
- 6 Was soll ich nehmen: CSSPath, RegEx oder XPath?
- 7 Was ist der Unterschied zwischen „Custom Extraction“ und „Custom Search“ im Screaming Frog?
Custom Extractions dank Screaming Frog 19 visuell definieren
Bis zur Veröffentlichung von Screaming Frog 19 im Juli 2023 waren die Custom Extractions für viele Nutzer ein Buch mit sieben Siegeln. Denn einzig über XPath, RegEx oder CSSPath konnte definiert werden, was aus der Seite ausgelesen werden soll. Diese Optionen gibt es natürlich weiterhin, aber eine visuelle Extraktion kam dazu.
Um eigene Daten auszulesen, muss in der Crawl-Konfiguration unter „Custom“ => „Custom Extraction“ über „Add“ (unten rechts) eine neue Extraktion erstellt werden. Um in den visuellen Modus zu kommen, klicke auf die kleine Weltkugel in der neu erstellten Zeile.
Wenn du den Screaming Frog auf Deutsch eingestellt hast, ist „Konfiguration“ => „Eigene“ => „Benutzerdefinierte Extraktion“ dein Klickpfad. Die Sprache kannst du übrigens unter „File“ => „Settings“ => „Language“ definieren.
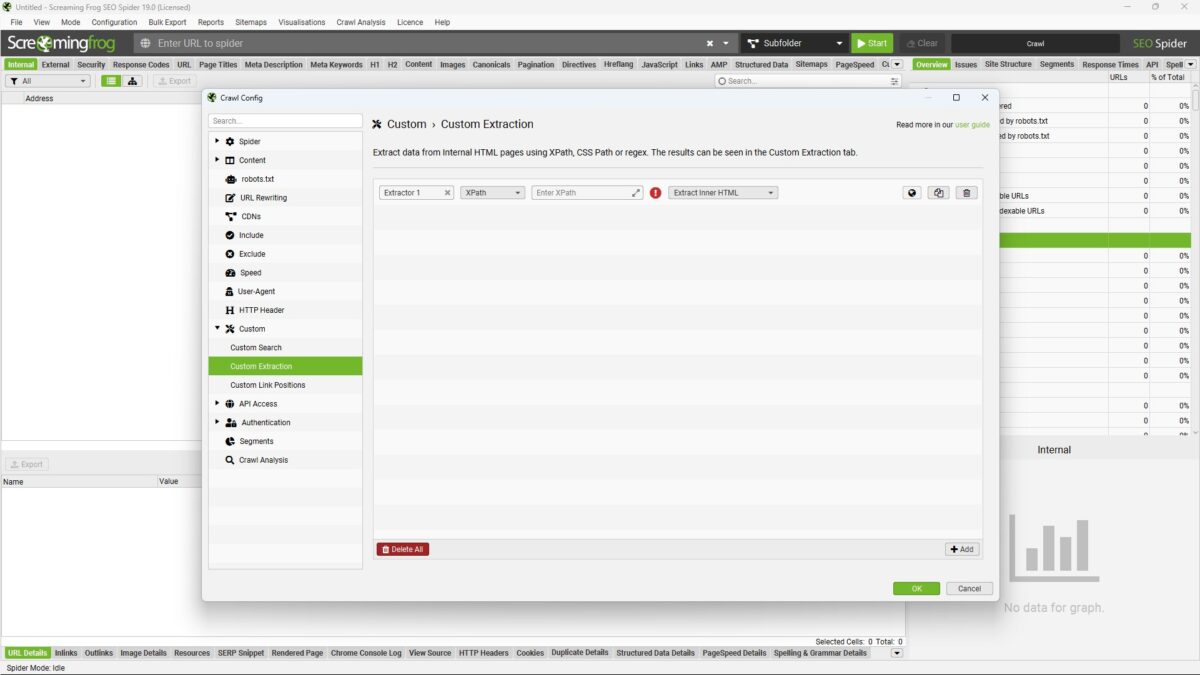
Nachdem du die Weltkugel (bzw. das Browser-Symbol) angeklickt hast, öffnet sich der interne Browser des Screaming Frog. Diesem gibst du jetzt eine Beispiel-URL an, die den von dir gewünschten Inhalt enthält.
Du kannst anschließend entweder auf der Web Page, dem „Rendered HTML“ oder dem „Source HTML“ per Mausklick den gewünschten Extraktionsbereich auswählen. In meinem Beispiel möchte ich den ersten Absatz der Seminarbeschreibung meines 121Watt Screaming Frog Seminars ziehen.
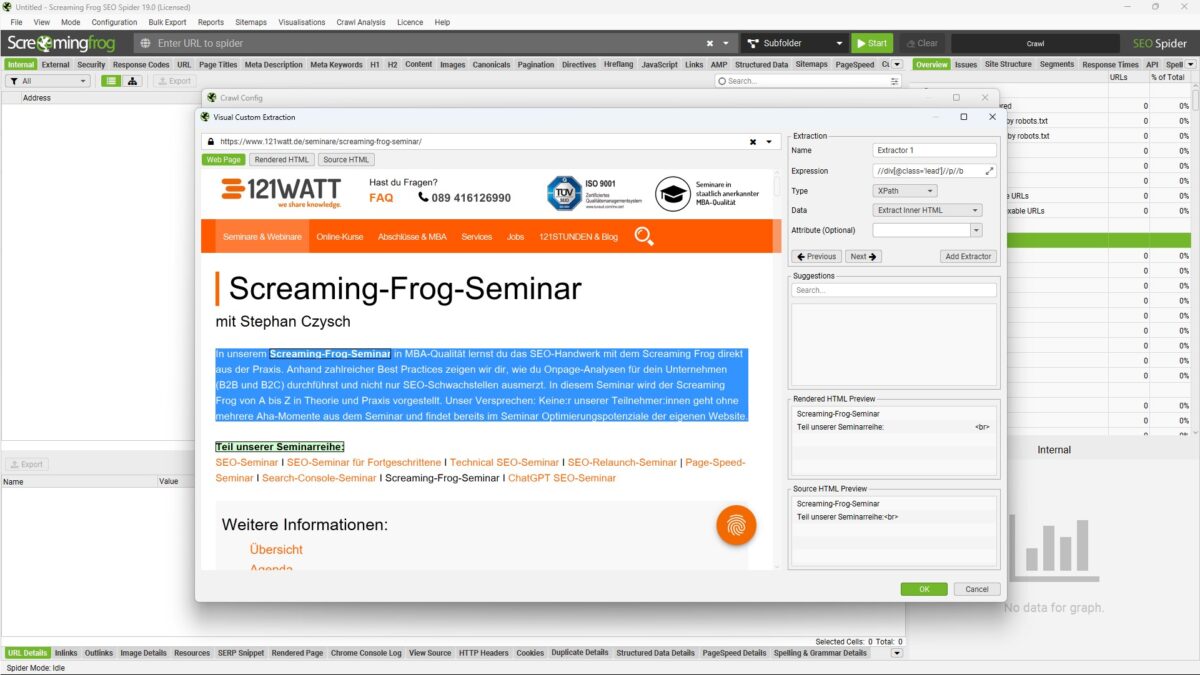
Im oberen rechten Bereich siehst du alle Einstellungen für deine Custom Extraction. Hier kannst du dieser einen Namen geben und unter anderem definieren, was ausgelesen werden soll. Durch einen Klick auf „Add Extractor“ wird die von dir erstellte Extraktion angelegt.
Total einfach, oder? Informationen zur klassischen Extraction mit dem Screaming Frog findest du im weiteren Verlauf des Artikels.
* Ende des Updates *
Dank Custom-Extractions ist mit dem Screaming Frog alles auslesbar
Von Haus aus liest der Screaming Frog jegliche Daten aus, die den HTML-Standards entsprechen. Seitentitel, Meta Description, h1-Überschriften – da es hier vorgegebene Strukturen gibt, können diese Elemente problemlos extrahiert werden.
Schwieriger wird es mit allem, was nicht über verschiedene Webauftritte hinweg identisch in HTML ausgezeichnet ist. So gibt es z.B. für den Textbereich keine vorgegebene Klasse. Doch der Screaming Frog kann alles auslesen, was auf einer Seite vorhanden ist.
Möglich machen das die manuell einstellbaren „Custom Extractions“. In diesen wird definiert, wie sich das gewünschte Element identifizieren lässt. Wird das gesuchte Element auf der Seite gefunden, dann wird der Crawl um die gefundenen Werte angereichert. Doch wie identifiziert man den richtigen XPath, RegEx oder CSSPath? Und was ist das überhaupt?
Den DOM mit XPath, regulären Ausdrücken und CSSPath durchsuchen
Vereinfacht gesagt, besteht eine Webseite nur aus Text, der mittels HTML formatiert wird. Im Browser wird die Seite in eine Objektstruktur übertragen, den sogenannten DOM für Document Object Modell. Diese Struktur kann man sich wie einen Baum vorstellen.
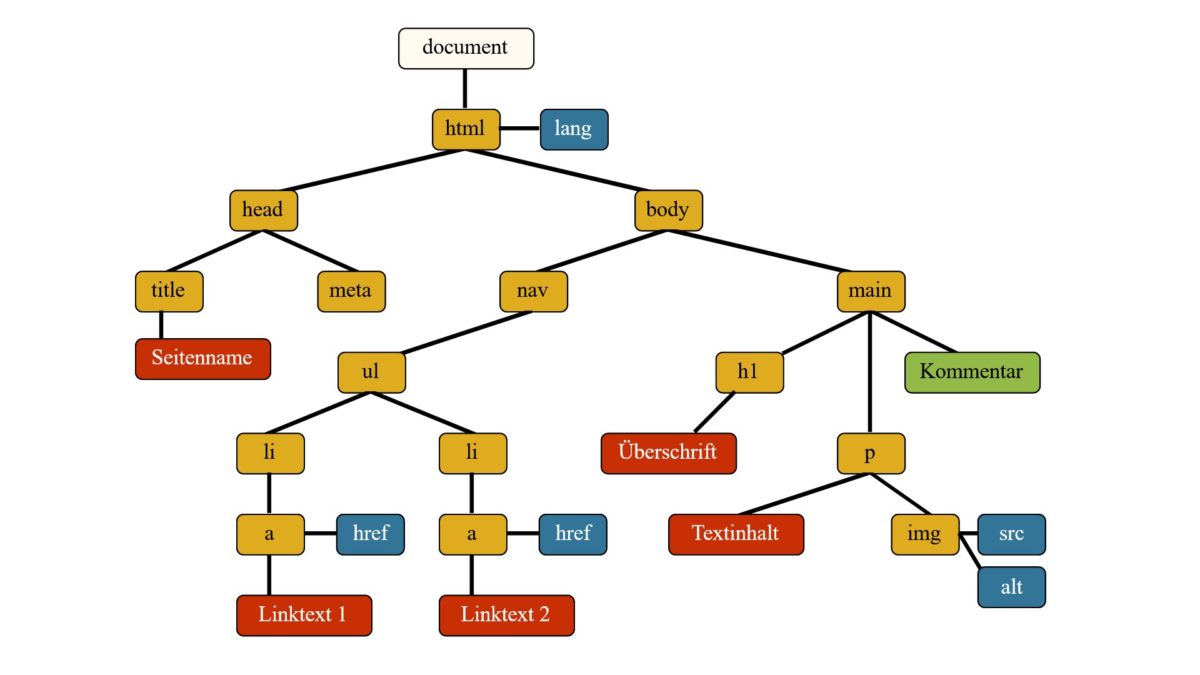
So besteht das HTML-Dokument aus dem <head> und dem <body>. Innerhalb dieser beiden Bereiche gibt es verschiedene Knoten, beispielsweise den <title> mit dem dazugehörigen Text im Head.
Innerhalb des Baums kann jeder Knoten über den dazugehörigen Pfad angesprochen werden. Wenn wir uns die Beispielgrafik von selfhtml.org anschauen, dann befindet sich die h1-Überschrift im HTML => BODY => MAIN => h1.
Durch das Durchlaufen dieses Pfades (englisch: Path) lässt sich der Knoten adressieren. Und dadurch deren Inhalt auslesen. Genau das ist mit XPath, CSSPath und regulären Ausdrücken möglich.
Beispiel-XPaths für den Screaming Frog
Etwas ganz Grundsätzliches: ein // bezieht sich bei XPath auf alle Knoten, die einen bestimmten Namen wie „h3“ haben. Ein //div würde also alle Div-Container (bzw. deren Inhalt auslesen). Das ist meistens mehr als man möchte.
Hier kommen die Klassen ins Spiel. Über den Namen von Klassen (oder IDs) lässt sich ein bestimmtes HTML-Element noch genauer ansprechen.
Nehmen wir folgendes Beispiel
- <div class=“main-content“>Hallo</div>
- <div class=“main“>123</div>
//div würde sowohl „main-content“ als auch „main“ ansprechen. Möchte ich nur den Inhalt von „main-content“ ansprechen, kann ich das über ein //div[@class=“main-content“] tun. Das definiert, dass ein <div> gesucht wird, dass den Klassenbezeichner „main-content“ verwendet.
Es sind aber auch noch feinere oder gröbere Angaben möglich. So würde //div[contains(@class ,’main‘)] definieren, dass im Klassenbezeichner „main“ enthalten sein soll. Entsprechend trifft das auf das beide Beispiele oben zu.
Eine Verfeinerung ist unter anderem durch [] möglich. So zieht ein //div[contains(@class ,’main‘)][1] nur das erste <div>, das „main“ im Klassennamen nutzt.
Neben der expliziten Ansprache des x-ten Treffers mit [], ist es auch möglich, die ersten x-Elemente zu extrahieren. Doch schauen wir einfach auf ein paar Beispiele für Custom Extractions zum direkten Kopieren.
| XPath Beispiel | Was macht der XPath? |
|---|---|
//h3 | Zieht alle h3-Überschriften |
count(//h3) | Zählt die Anzahl der h3-Überschriften und liefert den Wert. Dazu im Drop-Down „Function Value“ auswählen |
/descendant::h3[1] | Extrahiert über den Wert in der eckigen Klammer die x-te h3-Überschrift (in diesem Fall die erste h3) |
/descendant::h3[position() >= 0 and position <= 3] | Extrahiert die ersten drei h3-Überschriften durch die Angabe der minimalen und maximalen Position |
//*[@hreflang]/@hreflang | Zieht die Länderwerte aus den hreflang-Angaben heraus |
//*[@itemtype]/@itemtype | Ermöglicht auch ohne aktiviertes „Structured data extraction“ das Auslesen der Schema.org-Typen (wie Local, Product) |
//meta[starts-with(@property, 'og:title')]/@content | Extrahiert den og:title (wird i.d.R. für das Teilen in sozialen Netzwerken genutzt) |
//*[@class="content"] | Liest alle HTML-Klassen aus, die die Klasse „content“ (für das Styling) verwenden |
//div[@class="content"]//a/@href | Zieht alle Link-Ziele heraus, die sich in <div> mit der Klasse „content“ befinden |
//iframe[contains(@src ,'www.youtube.com/embed/')] | Extrahiert alle Iframes, die sich auf URLs mit der Quelle (src für source) www.youtube.com beziehen |
//div[contains(@class ,'main')]//h1|//a[@class="comments-link"] | Hier werden zwei Suchen mit dem „| “ kombiniert. Das Ergebnis: Die Treffer werden hintereinander ausgegeben, wodurch eine Zuordnung möglich ist. In diesem Fall würde die h1 sowie der Inhalt von „comment-link“ ausgelesen |
XPaths mit dem Browser generieren
Die „Developer Toolbar“ vieler Browser hilft dabei, den XPath zu generieren. Durch einen Rechtsklick und gefolgt von „untersuchen“, oder alternativ durch F12 auf der Tastatur lässt sich die Toolbar aktivieren.
Über das Symbol mit dem Pfeil oben links kann auf der Seite das gewünschte Element direkt angeklickt und damit im DOM markiert werden. In diesem Fall habe ich den Breadcrumb-Pfad markiert.
Durch einen Rechtsklick in der Developer Toolbar kann unter „Copy“ ein Xpath oder Full XPath generiert werden. Dieser sieht in diesem Fall so aus:
- XPath: /html/body/nav/div[2]/div/div/nav
- Full XPath: /html/body/nav/div[2]/div/div/nav
In diesem Fall unterscheiden sich die beiden Pfade nicht.
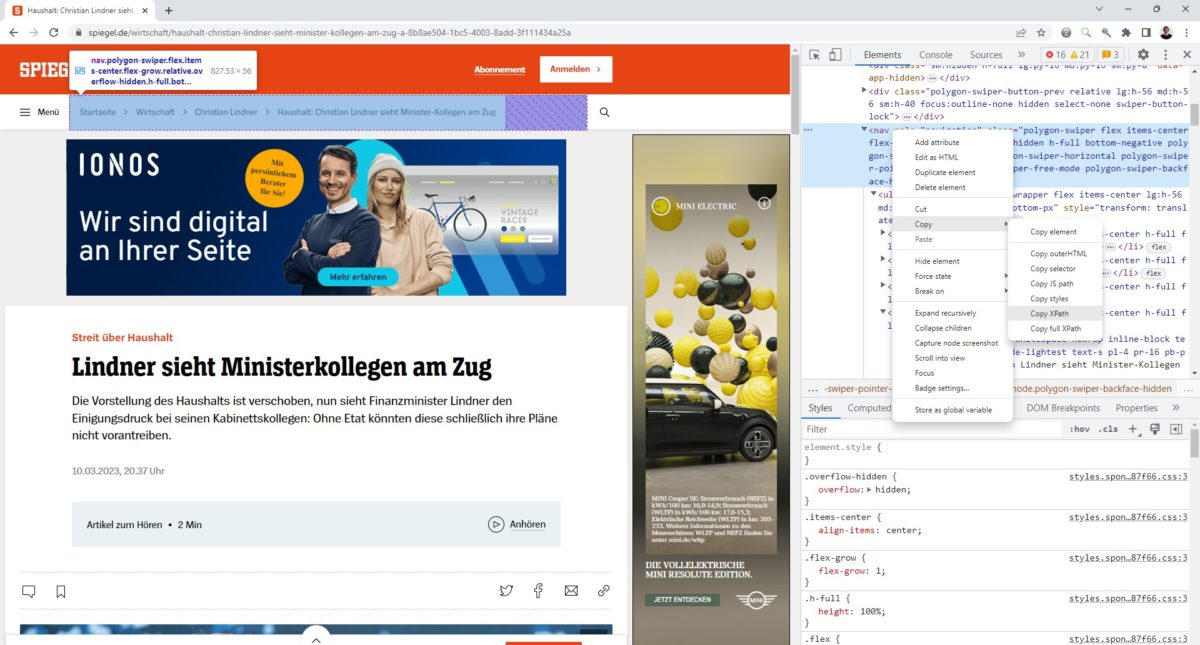
Solche XPaths haben ein Problem: Ist der Seitenaufbau anders, dann laufen sie ins Leere oder extrahieren etwas „Falsches“. Deshalb ist es immer besser, einen möglichst genauen XPath durch die Nutzung von IDs oder Klassen zu verwenden.
Im nachfolgenden Beispiel habe ich mich auf das <nav>-Element mit „role=’navigation’“ bezogen. Das sieht fehlerrobuster aus, trifft aber mehrere Elemente.
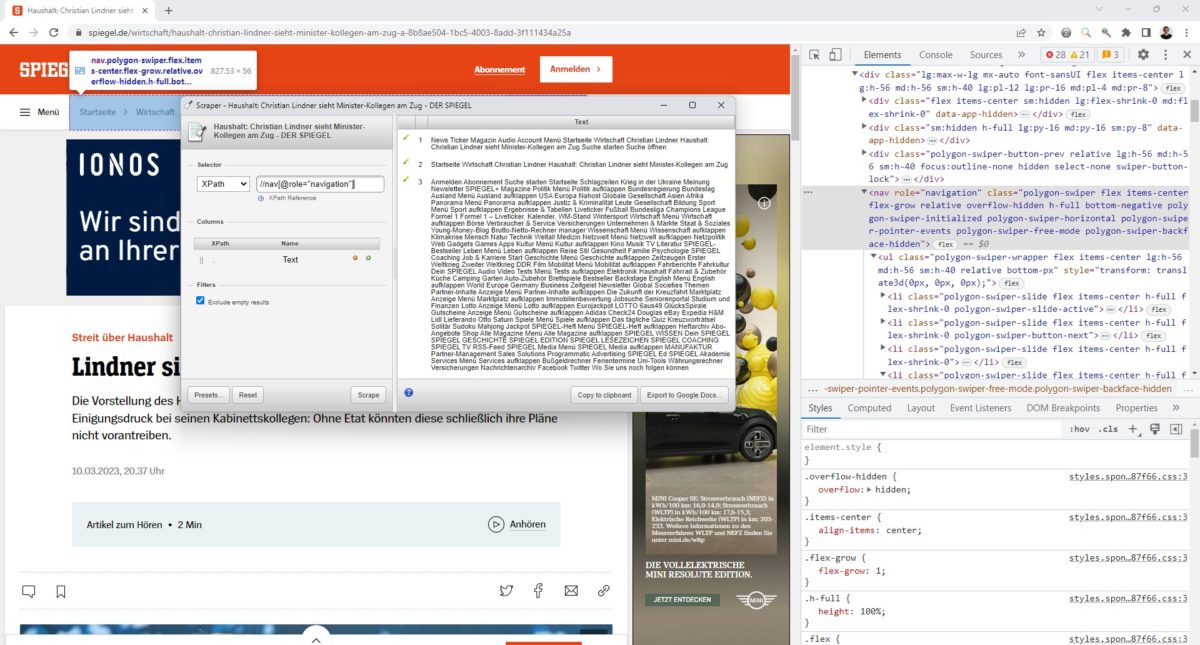
Deshalb wäre eine weitere Spezifikation notwendig, um genau den gewünschten Bereich zu extrahieren.
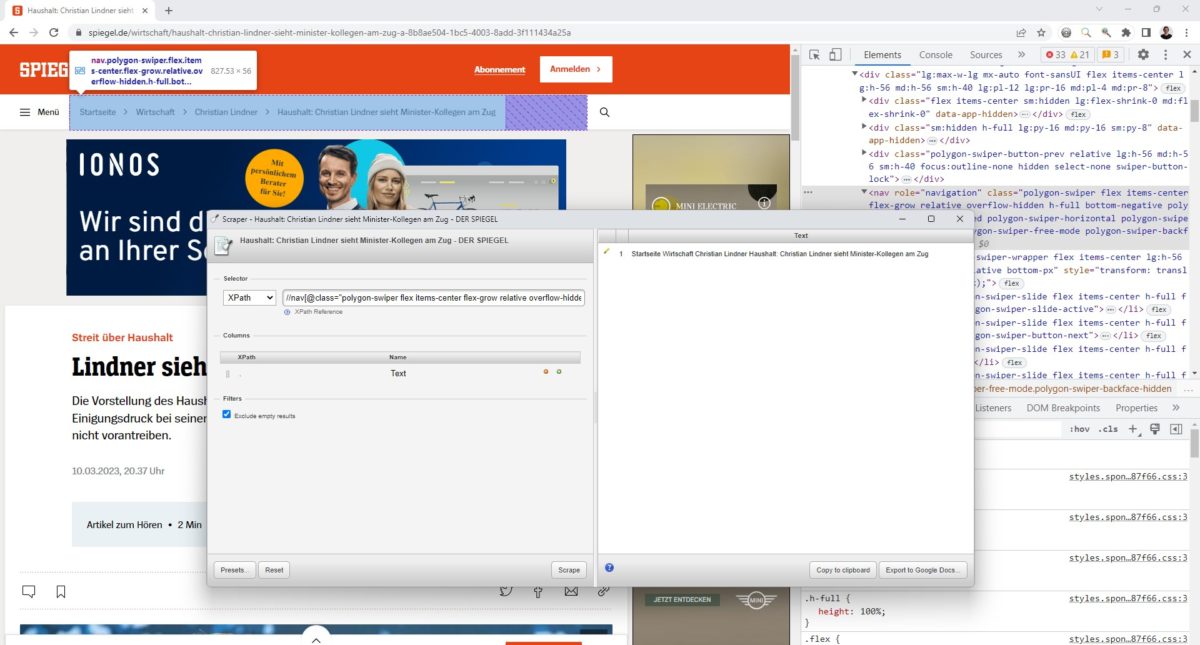
Um XPaths zu testen, nutze ich gerne das „Scraper Plugin„. Dieses habe ich in meinem Beitrag zu SEO Browserplugins vorgestellt.
Du siehst: Manchmal dauert es etwas, bis der „perfekte“ XPath gefunden wurde. Und vor allem: Viele Wege führen nach Rom. Manchmal ist es einfacher, ein nicht perfektes Ergebnis mit Excel zu säubern, als stundenlang am XPath zu feilen.
Was soll ich nehmen: CSSPath, RegEx oder XPath?
in 99% der Fälle liefert mir ein XPath das, was ich suche. Die beiden Alternativen sind aber genauso gut geeignet, um Daten zu extrahieren. Aber besonders reguläre Ausdrücke (RegEx) sind eine Wissenschaft für sich.
Was ist der Unterschied zwischen „Custom Extraction“ und „Custom Search“ im Screaming Frog?
Der Screaming Frog hat noch eine weitere mächtige Funktion: Custom Search. mit der Custom Search kannst du schauen, ob etwas (nicht) auf einer Seite ist – aber nicht den Inhalt auslesen. Und genau das ist der Unterschied zwischen zur „Custom Extraction“.
Weitere Beispiele für Custom Extractions mit dem Screaming Frog gibt es bei diesen Seiten:
- https://www.screamingfrog.co.uk/web-scraping/
- https://uproer.com/articles/screaming-frog-custom-extraction-xpath-regex/


 auf den Unternehmenserfolg einzahlen")
Schreibe einen Kommentar