Zu den Lieblingswörtern jedes SEOs gehört „Duplicate Content„. Doch was versteht man unter diesem Schreckgespenst jedes Webmasters und wie wirkt sich Duplicate Content, also doppelte Inhalte, aus?
Inhalt
Was ist Duplicate Content?
Von Duplicate Content, abgekürzt mit DC, wird gesprochen, wenn exakt derselbe oder auch ein sehr ähnlicher Inhalt („Near Duplicate Content„) unter verschiedenen Webadressen hinweg zur Verfügung steht. Dies kann entweder domainintern sein oder über Domaingrenzen hinweg. Bei letzterem Fall muss zwischen eigenen Domains und fremden Domains unterschieden werden.
Duplicate Content identifizieren
Um doppelte Inhalte zu identifizieren, können folgende Strategien angewendet werden:
- Google Suche mit dem gesuchten Textschnippsel in Anführungszeichen (z.B. „ist dieser Text mehrfach in Verwendung“)
- Verwendung von Tools wie www.copyscape.com
- Crawling der eigenen Website
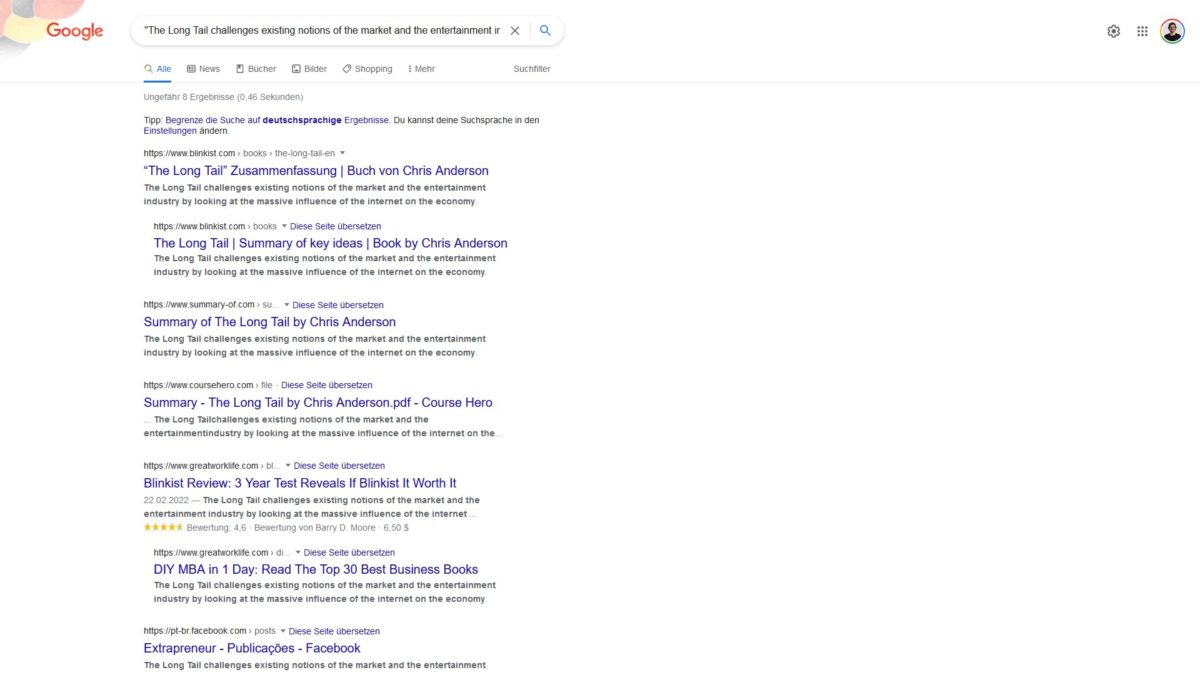
Duplicate Content über die Google-Suche finden
Mittels des „“ Suchoperators kann nach exakten Textfragmenten gesucht werden. Gegebenenfalls sollte der site:domain.de-Befehl verwendet werden, um nur auf der eigenen Seite nach den zwischen den Anführungszeichen stehenden Worten zu suchen.
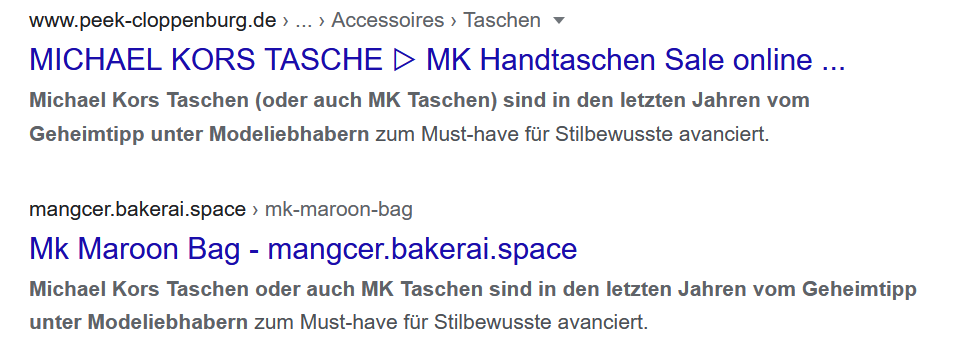
Im Beispiel ist alles gut: Der Text zu Michael Kors Taschen wurde nicht nur auf der Zielseite von peek-cloppenburg.de, sondern auch auf weiteren Domains gefunden.
Duplicate Content mit Copyscape finden
Mittels des Tools Copyscape (www.copyscape.com) kann im Netz nach Dokumenten gesucht werden, die dem übergebenen Dokument gleichen. Natürlich gibt es noch weitere Tools wie z.B. www.plagiarismchecker.co.
Doppelte Inhalte über ein Crawling der eigenen Website finden
Mit Crawlern kann die eigene Webseite untersucht werden. Gegebenenfalls lassen sich durch die Crawlingergebnisse Seiten identifizieren, die sich (intern) ähneln. Der einfachste Weg ist auch hier die Betrachtung doppelter Seitenelemente wie dem Seitentitel oder h1 Überschriften.

Duplicate Content über unterschiedliche, eigene Domains hinweg
Angenommen, man verwendet dieselben Inhalte für unterschiedliche Domains, die auf verschiedene Zielmärkte (z.B. Deutschland und Österreich) ausgerichtet sind, ist dank des HTML-Tags ‚rel=“alternate“ hreflang=““‚ eine Umgehung von möglichen Duplicate Content Problemen gewährleistet. Mehr zu diesem Tag ist im Google-Blog zu finden.
Warum ist Duplicate Content problematisch?
Für Nutzer erhöht sich der Mehrwert nicht, wenn identische oder nahezu identische Inhalte im Netz gefunden werden können. Selbes gilt für Suchmaschinen, die zudem kein Interesse daran haben, exakt identische Informationen als Top-Suchtreffer zu platzieren.
Das Hauptproblem von Duplicate Content liegt darin, dass sich Rankingsignale auf verschiedene Adressen verteilen. So senden mehrere Adressen dieselben inhaltlichen Relevanzsignale und Suchmaschinen müssen entscheiden, welches dieser Dokumente die relevanteste Version ist.
Stephan Czysch
Anstatt rankingrelevante Signale, allen voran Verlinkungen, auf verschiedenen Adressen zu verteilen, sollen diese besser auf genau einer Adresse zusammengefasst werden. Das ist über eine Weiterleitung oder Löschung der Varianten möglich, oder über deren Zusammenfassung auf eine Variante per Canonical-Tag.



Schreibe einen Kommentar